Deal of The Day! Hurry Up, Grab the Special Discount - Save 25% - Ends In 00:00:00 Coupon code: SAVE25
Free Preparation Discussions
Nutanix Exam NCM-MCI-5.15 Topic 2 Question 4 Discussion
Actual exam question for
Nutanix's
NCM-MCI-5.15 exam
Question #: 4
Topic #: 2
[All NCM-MCI-5.15 Questions]
Topic #: 2
An alert about RX errors on eth2 on a node is reported in the cluster. The administrator logs in to the CVM in question, checks the ping_* files in the data/logs/syststats folder, and notices intermittent ping loss.
The node in question has the following network configuration:
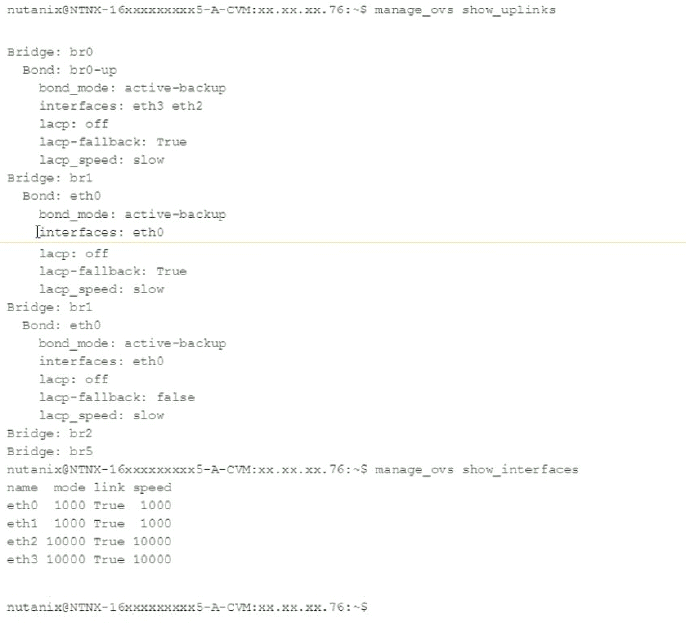
Which action should be used to troubleshoot without disrupting the VMs running on this node?
Suggested Answer:
D
Currently there are no comments in this discussion, be the first to comment!