Free Preparation Discussions
Microsoft 70-775 Exam Questions
- Topic 1: Administer and Provision HDInsight Clusters Implement Big Data Batch Processing Solutions Implement Big Data Interactive Processing Solutions Implement Big Data Real-Time Processing Solutions
Free Microsoft 70-775 Exam Actual Questions
Note: Premium Questions for 70-775 were last updated On 15-07-2019 (see below)
Note: This question is part of a series of questions that use the same scenario. For your convenience, the scenario is repeated in each question. Each question presents a different goal and answer choices, but the text of the scenario is exactly the same in each question in this series.
You are planning a big data infrastructure by using an Apache Spark cluster in Azure HDInsight. The cluster has 24 processor cores and 512 GB of memory.
The architecture of the infrastructure is shown in the exhibit. (Click the Exhibit button.)
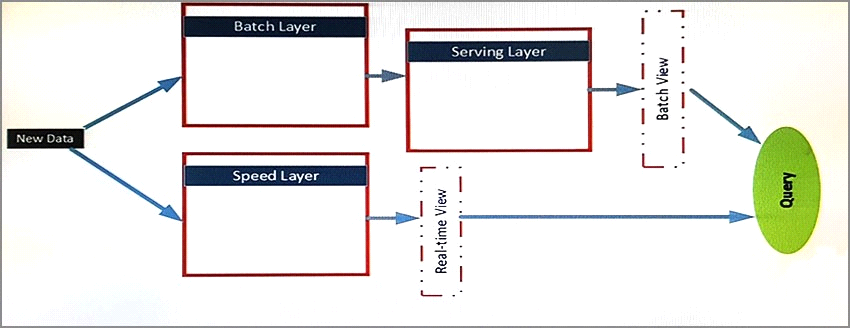
The architecture will be used by the following users:
Support analysts who run applications that will use REST to submit Spark jobs.
Business analysts who use JDBC and ODBC client applications from a real-time view. The business analysts run monitoring queries to access aggregate results for 15 minutes. The results will be referenced by subsequent queries.
Data analysts who publish notebooks drawn from batch layer, serving layer, and speed layer queries. All of the notebooks must support native interpreters for data sources that are batch processed. The serving layer queries are written in Apache Hive and must support multiple sessions. Unique GUIDs are used across the data sources, which allow the data analysts to use Spark SQL.
The data sources in the batch layer share a common storage container. The following data sources are used:
Hive for sales data
Apache HBase for operations data
HBase for logistics data by using a single region server
You need to ensure that the data analysts can use the notebooks.
What should you install?
You have an Apache Hive cluster in Azure HDInsight.
You plan to ingest on-premises data into Azure Storage.
You need to automate the copying of the data to Azure Storage.
Which tool should you use?
You have an Apache HBase cluster in Azure HDInsight.
You plan to use Apache Pig, Apache Hive, and HBase to access the cluster simultaneously and to process data stored in a single platform.
You need to deliver consistent operations, security, and data governance.
What should you use?
You have several Linux-based and Windows-based Azure HDInsight clusters. The clusters are indifferent Active Directory domains.
You need to consolidate system logging for all of the clusters into a single location. The solution must provide near real-time analytics of the log dat
a.
What should you use?
You have an Apache Spark job.
The performance of the job deteriorates over time.
You plan to debug the job.
You need to gather information that you can use to debug the job.
Which tool should you use?
- Select Question Types you want
- Set your Desired Pass Percentage
- Allocate Time (Hours : Minutes)
- Create Multiple Practice tests with Limited Questions
- Customer Support
Currently there are no comments in this discussion, be the first to comment!