Free Preparation Discussions
Microsoft 70-773 Exam Questions
- Microsoft MCSA: Machine Learning Certifications
- Microsoft MCSE: Data Management and Analytics Certifications
- Topic 1: Read data with R Server Visualize data Process data with rxDataStep Manage data sets Process text using RML packages Build and use partitioning models Evaluate models and tuning parameters Create additional models using RML packages Optimize
Free Microsoft 70-773 Exam Actual Questions
Note: Premium Questions for 70-773 were last updated On 25-06-2019 (see below)
Note: This question is part of a series of questions that use the same scenario. For your convenience, the scenario is repeated in each question. Each question presents a different goal and answer choices, but the text of the scenario is exactly the same in each question in this series.
Start of repeated scenario
You are developing a Microsoft R Open solution that will leverage the computing power of the database server for some of your datasets.
You are performing feature engineering and data preparation for the datasets.
The following is a sample of the dataset.
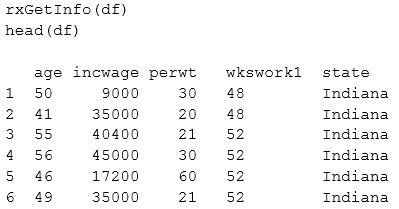
End of repeated scenario.
You have the following R code.

Which function determines the variable?
You have an Apache Hadoop Hive data warehouse. RevoScalerR is not installed.
You need to sort the data according to the variables in the dataset.
What should you do?
You have a slow Map Reduce job.
You need to optimize the job to control the number of mapper and runner tasks.
Which function should you use?
You have cloud and on-premises resources that include Microsoft SQL Server and a big data environment in Apache Hadoop.
You have 50 billion fact records.
You need to build time series models to execute forecasting reports on the fact records.
What should you use?
You are planning the compute contexts for your environment.
You need to execute rx-function calls in parallel.
What are three possible compute contexts that you can use to achieve this goal? Each correct answer presents a complete solution.
NOTE: Each correct selection is worth one point.
- Select Question Types you want
- Set your Desired Pass Percentage
- Allocate Time (Hours : Minutes)
- Create Multiple Practice tests with Limited Questions
- Customer Support
Currently there are no comments in this discussion, be the first to comment!