Free Preparation Discussions
Free Microsoft DP-100 Exam Dumps - Page 5
MultipleChoice
You plan to use .a Deep learning Virtual Machine (DLVM) to train deep learning models using Compute Unified Device Architecture (CUDA) computations.
You need to configure the IXVM to support CUOA
What should you implement?
OptionsMultipleChoice
You are determining if two sets of data are significantly different from one another by using Azure Machine Learning Studio.
Estimated values in one set of data may be more than or less than reference values in the other set of data. You must produce a distribution that has a constant. Type I error as a function of the correlation.
You need to produce the distribution.
Which type of distribution should you produce?
OptionsMultipleChoice
You are creating a machine learning model.
You need to identify outliers data.
Which two visualizations can you use? Each correct answer presents a complete solution.
NOTE: Each correct selection is worth one point.
OptionsHotspot
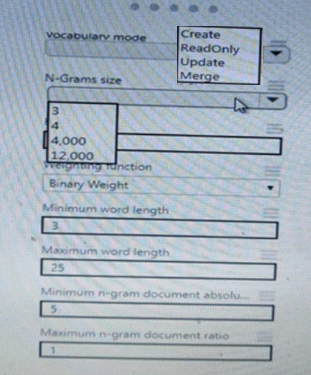
You are performing sentiment analysis using a CSV file that includes 12.0O0 customer reviews written in a short sentence format. You add the CSV file to Azure Machine Learning Studio and Configure it as the starting point dataset of an experiment. You add the Extract N-Gram Features from Text module to the experiment to extract key phrases from the customer review column in the dataset.
You must create a new n-gram text dictionary from the customer review text and set the maximum n-gram size to trigrams.
You need to configure the Extract N Gram features from Text module.
What should you select? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
MultipleChoice
You are evaluating, a completed binary classification machine learning model.
You need to use the precision as the evaluation metric.
Which visualization should you use?
OptionsHotspot
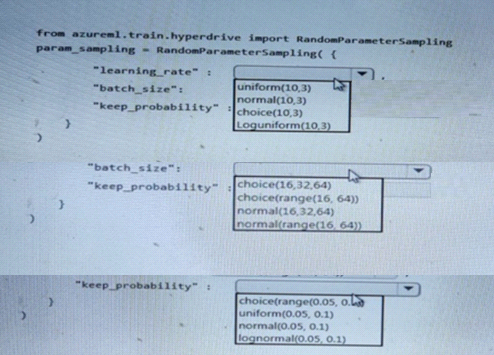
You are using the Azure Machine Learning Service to automate hyper par a meter exploration of your neural network classification model.
You must define the hyper parameter space to automatically tune hyper parameters using random sampling according to following requirements:
* Learning rate must be selected from a normal distribution with a mean value of 10 and a standard deviation of 3.
* Batch size must be 16, 32 and 64.
* Keep probability must be a value selected from a uniform distribution between the range of 0.05 and 0.1.
You need to use the par am .sampling method of the Python API for the Azure Machine Learning Service. How should you complete the code segment? To answer, select the appropriate Options in the answer area.
NOTE: Each correct selection is worth one point.
Hotspot
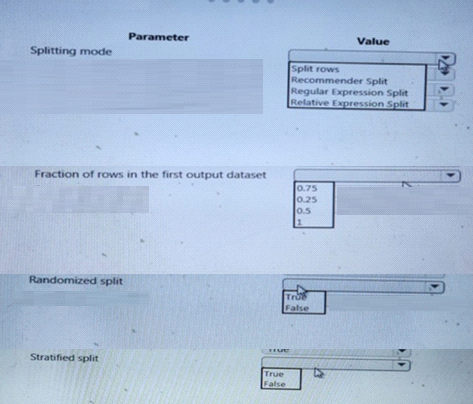
You are performing a classification task in Azure Machine learning Studio.
You must prepare balanced testing and training samples based on a provided data set.
Warning samples based on a provided data set.
You need to split the data with a 0.75:0.25.
Which value should you use for each parameter? To answer, select the appropriate options m the answer area.
NOTE: Each correct selection is worth one point.
Hotspot
You are tuning a hyperparameter for an algorithm. The following table shows a data set with different hyperparameter, training error, and validation errors.
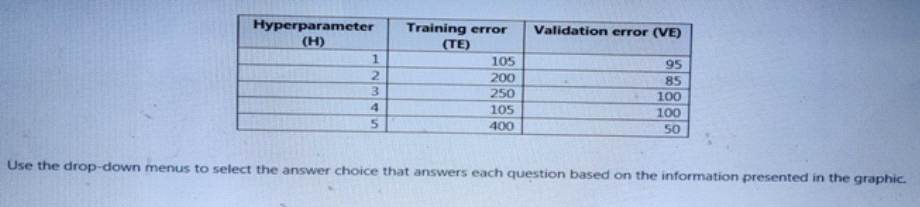
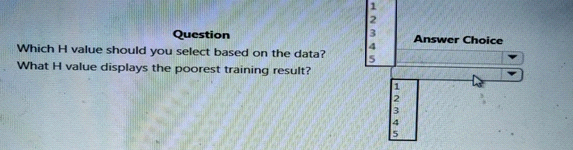
DragDrop
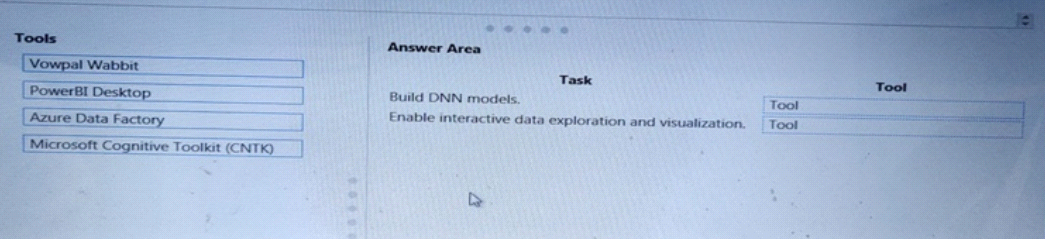
You configure a Deep Learning Virtual Machine for Windows.
You need to recommend tools and frameworks to perform the following:
Build deep rwur.il network (DNN) models.
Perform interactive data exploration and visualization.
Which tools and frameworks should you recommend? To answer, drag the appropriate tools to the correct tasks. Each tool may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content.
NOTE: Each correct selection is worth one point.




Hotspot
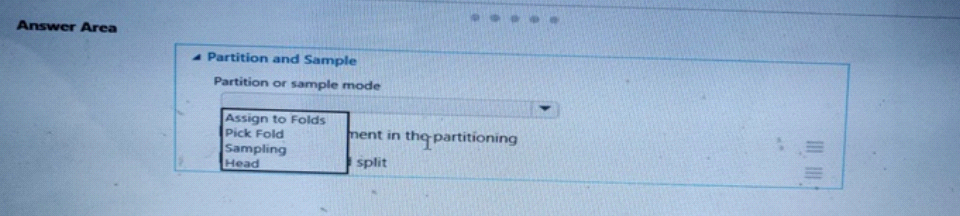
You have a dataset contains 2,000 rows. You arc building a machine learning classification model by using Azure Machine Learning Studio. You add a Partition and Sample module to the experiment.
You need to configure the module. You must meet the following requirements:
* Divide the data into subsets.
* Assign the rows into folds using a round-robin method.
* Allow rows in the dataset to be reused.
How should you configure the module? To answer select the appropriate Options m the dialog box in the answer area.
NOTE: Each correct selection is worth one point.