Free Preparation Discussions
Free Microsoft DP-100 Exam Dumps - Page 4
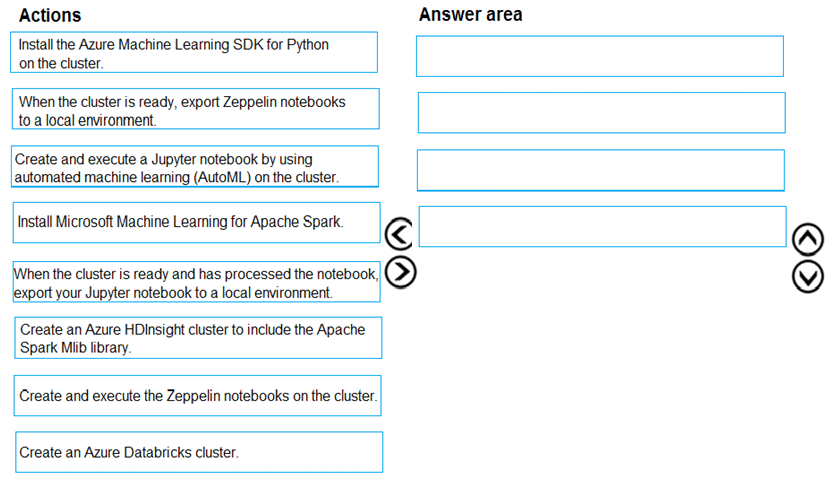
DragDrop
You are building an intelligent solution using machine learning models.
The environment must support the following requirements:
* Data scientists must build notebooks in a cloud environment
* Data scientists must use automatic feature engineering and model building in machine learning pipelines.
* Notebooks must be deployed to retrain using Spark instances with dynamic worker allocation.
* Notebooks must be exportable to be version controlled locally.
You need to create the environment.








DragDrop
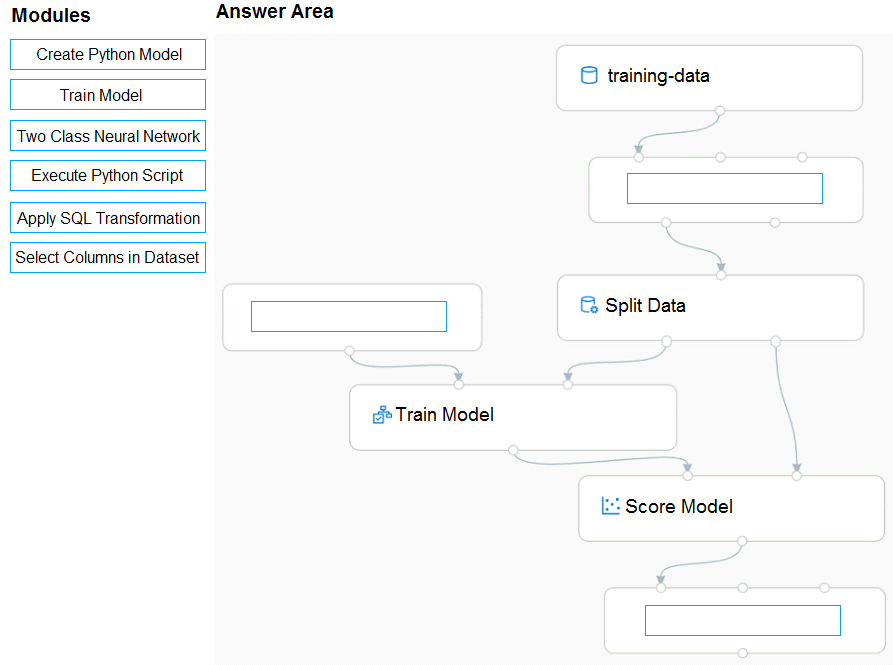
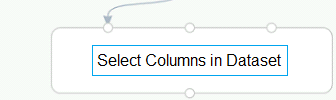
You create a training pipeline using the Azure Machine Learning designer. You upload a CSV file that contains the data from which you want to train your model.
You need to use the designer to create a pipeline that includes steps to perform the following tasks:
* Select the training features using the pandas filter method.
* Train a model based on the naive_bayes.GaussianNB algorithm.
* Return only the Scored Labels column by using the query SELECT [Scored Labels] FROM t1;
Which modules should you use? To answer, drag the appropriate modules to the appropriate locations. Each module name may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content.
NOTE: Each correct selection is worth one point.












MultipleChoice
A set of CSV files contains sales records. All the CSV files have the same data schema.
Each CSV file contains the sales record for a particular month and has the filename sales.csv. Each file in stored in a folder that indicates the month and year when the data was recorded. The folders are in an Azure blob container for which a datastore has been defined in an Azure Machine Learning workspace. The folders are organized in a parent folder named sales to create the following hierarchical structure:

At the end of each month, a new folder with that month's sales file is added to the sales folder.
You plan to use the sales data to train a machine learning model based on the following requirements:
* You must define a dataset that loads all of the sales data to date into a structure that can be easily converted to a dataframe.
* You must be able to create experiments that use only data that was created before a specific previous month, ignoring any data that was added after that month.
* You must register the minimum number of datasets possible.
You need to register the sales data as a dataset in Azure Machine Learning service workspace.
What should you do?
OptionsHotspot
You are a lead data scientist for a project that tracks the health and migration of birds. You create a multi-image classification deep learning model that uses a set of labeled bird photos collected by experts. You plan to use the model to develop a cross-platform mobile app that predicts the species of bird captured by app users.
You must test and deploy the trained model as a web service. The deployed model must meet the following requirements:
* An authenticated connection must not be required for testing.
* The deployed model must perform with low latency during inferencing.
* The REST endpoints must be scalable and should have a capacity to handle large number of requests when multiple end users are using the mobile application.
You need to verify that the web service returns predictions in the expected JSON format when a valid REST request is submitted.
Which compute resources should you use? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.

DragDrop
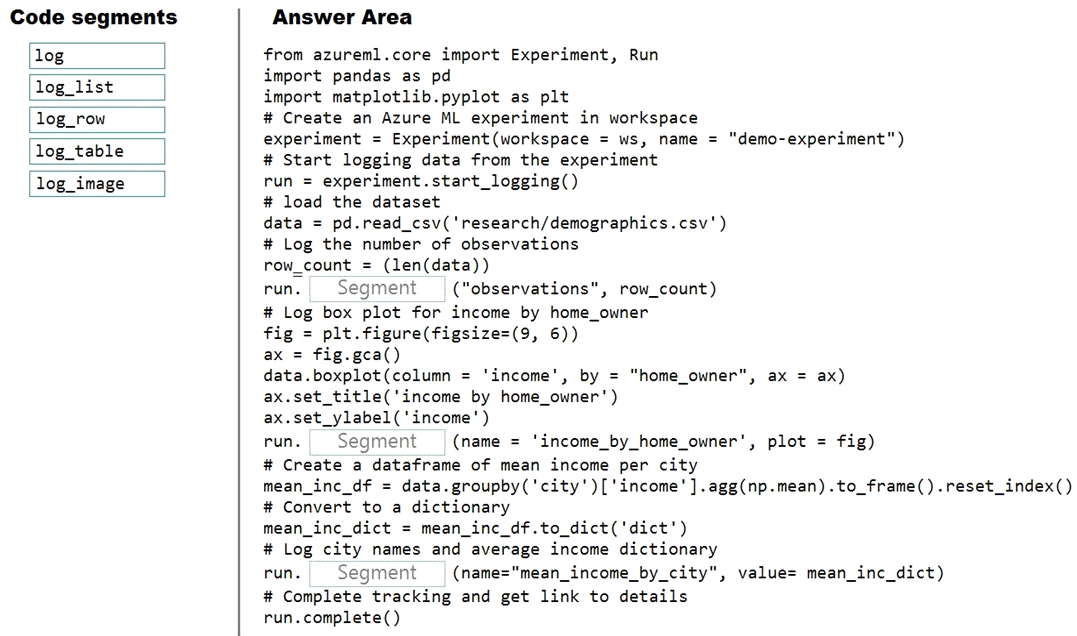
You plan to explore demographic data for home ownership in various cities. The data is in a CSV file with the following format:
age,city,income,home_owner
21,Chicago,50000,0
35,Seattle,120000,1
23,Seattle,65000,0
45,Seattle,130000,1
18,Chicago,48000,0
You need to run an experiment in your Azure Machine Learning workspace to explore the data and log the results. The experiment must log the following information:
* the number of observations in the dataset
* a box plot of income by home_owner
* a dictionary containing the city names and the average income for each city
You need to use the appropriate logging methods of the experiment's run object to log the required information.
How should you complete the code? To answer, drag the appropriate code segments to the correct locations. Each code segment may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content.
NOTE: Each correct selection is worth one point.





MultipleChoice
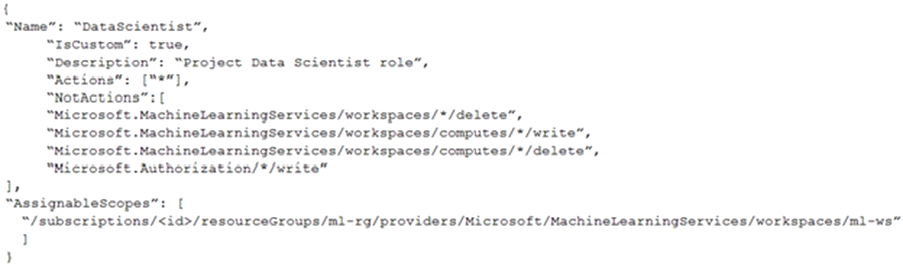
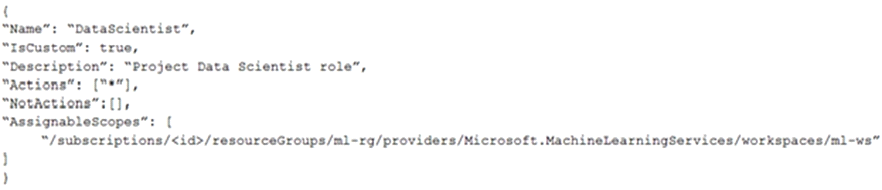
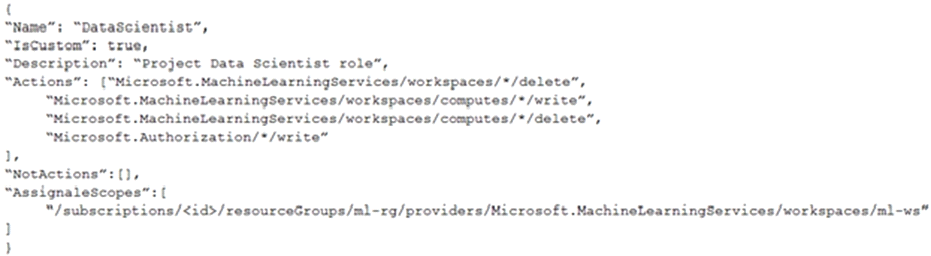
You create an Azure Machine Learning workspace.
You must create a custom role named DataScientist that meets the following requirements:
* Role members must not be able to delete the workspace.
* Role members must not be able to create, update, or delete compute resource in the workspace.
* Role members must not be able to add new users to the workspace.
You need to create a JSON file for the DataScientist role in the Azure Machine Learning workspace.
The custom role must enforce the restrictions specified by the IT Operations team.
Which JSON code segment should you use?
A)
B)
C)
D)
DragDrop
You need to visually identify whether outliers exist in the Age column and quantify the outliers before the outliers are removed.
Which three Azure Machine Learning Studio modules should you use in sequence? To answer, move the appropriate modules from the list of modules to the answer area and arrange them in the correct order.
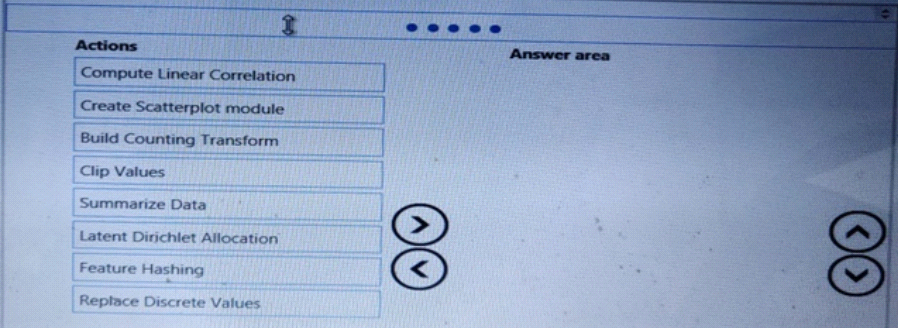



Create Scatterplot
Summarize Data
Clip Values
You can use the Clip Values module in Azure Machine Learning Studio, to identify and optionally replace data values that are above or below a specified threshold. This is useful when you want to remove outliers or replace them with a mean, a constant, or other substitute value.
References:
MultipleChoice
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You are a data scientist using Azure Machine Learning Studio.
You need to normalize values to produce an output column into bins to predict a target column.
Solution: Apply a Equal Width with Custom Start and Stop binning mode.
Does the solution meet the goal?
OptionsOrderList
YOU have a data-set that contains over 150 features. You use the dataset to train a Support Vector Machine (SVM) binary classifirer.
You need to use the Permutation Feature Importance module in Azure Machine Learning Studio to compute a set of feature importance scores for the dataset.
In which order should you perform the actions? To answer move al actions from from the list of Actions to the answer area and arrange them in the correct order.
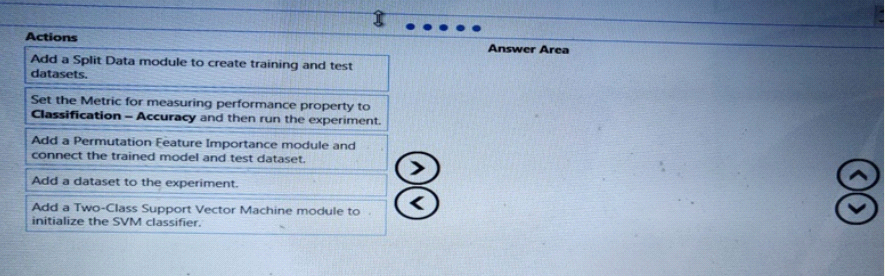
Hotspot
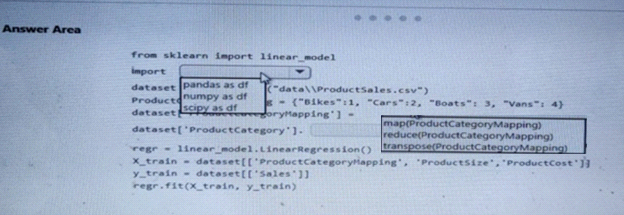
You are creating a machine learning model in Python. The provided dataset contains several numerical columns and one text column.
*Biker
*Cars
*Vans
*Boats
You are building a regression model using the scikit- learn Python package.
You need to transform the text data to be compatible with the scikit-learn Python package
How should you complete the code segment? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.