Free Preparation Discussions
Databricks Certified Generative AI Engineer Associate Exam Questions
- Topic 1: Design Applications: The topic focuses on designing a prompt that elicits a specifically formatted response. It also focuses on selecting model tasks to accomplish a given business requirement. Lastly, the topic covers chain components for a desired model input and output.
- Topic 2: Data Preparation: Generative AI Engineers covers a chunking strategy for a given document structure and model constraints. The topic also focuses on filter extraneous content in source documents. Lastly, Generative AI Engineers also learn about extracting document content from provided source data and format.
- Topic 3: Application Development: In this topic, Generative AI Engineers learn about tools needed to extract data, Langchain/similar tools, and assessing responses to identify common issues. Moreover, the topic includes questions about adjusting an LLM's response, LLM guardrails, and the best LLM based on the attributes of the application.
- Topic 4: Assembling and Deploying Applications: In this topic, Generative AI Engineers get knowledge about coding a chain using a pyfunc mode, coding a simple chain using langchain, and coding a simple chain according to requirements. Additionally, the topic focuses on basic elements needed to create a RAG application. Lastly, the topic addresses sub-topics about registering the model to Unity Catalog using MLflow.
- Topic 5: Governance: Generative AI Engineers who take the exam get knowledge about masking techniques, guardrail techniques, and legal/licensing requirements in this topic.
- Topic 6: Evaluation and Monitoring: This topic is all about selecting an LLM choice and key metrics. Moreover, Generative AI Engineers learn about evaluating model performance. Lastly, the topic includes sub-topics about inference logging and usage of Databricks features.
Free Databricks Databricks Certified Generative AI Engineer Associate Exam Actual Questions
Note: Premium Questions for Databricks Certified Generative AI Engineer Associate were last updated On Jun. 25, 2026 (see below)
A generative AI engineer is deploying an AI agent authored with MLflow's ChatAgent interface for a retail company's customer support system on Databricks. The agent must handle thousands of inquiries daily, and the engineer needs to track its performance and quality in real-time to ensure it meets service-level agreements. Which metrics are automatically captured by default and made available for monitoring when the agent is deployed using the Mosaic AI Agent Framework?
When deploying an agent via the Mosaic AI Agent Framework (which leverages Databricks Model Serving), operational metrics are captured automatically by default. These include system-level telemetry such as the number of requests per second (volume), the time taken for the model to respond (latency), and the rate of 4xx/5xx HTTP errors. These are essential for monitoring Service Level Agreements (SLAs). However, Quality metrics (B), such as correctness, groundedness, or adherence to custom guidelines, cannot be determined 'automatically' by the serving infrastructure because they require either human feedback or an LLM-as-a-judge evaluation (using Databricks Agent Evaluation). While Databricks makes it easy to generate quality metrics using the mlflow.evaluate API or the inference table, they are not 'default operational metrics' that appear without additional evaluation configuration.
A Generative AI Engineer has been reviewing issues with their company's LLM-based question-answering assistant and has determined that a technique called prompt chaining could help alleviate some performance concerns. However, to suggest this to their team, they have to clearly explain how it works and how it can benefit their question-answering assistant. Which explanation do they communicate to the team?
Prompt chaining is a fundamental design pattern in LLM application development used to handle complexity. Instead of sending a single, massive, and highly complex prompt to an LLM---which often results in reasoning errors or hallucinations---chaining breaks the logic into a sequence of smaller, targeted steps. For example, a legal assistant might first chain a step to 'identify the legal jurisdiction,' followed by a step to 'extract relevant statutes,' and finally a step to 'summarize the findings.' This modularity improves reliability because each prompt has a narrower focus, making it easier for the model to follow instructions accurately. While it may actually increase latency (contradicting B) and cost (contradicting D) due to multiple API calls, the primary engineering benefit is the significant boost in the quality and robustness of the output. It also allows for intermediate validation and error handling between steps, which is impossible in a single-call architecture.
A Generative Al Engineer would like an LLM to generate formatted JSON from emails. This will require parsing and extracting the following information: order ID, date, and sender email. Here's a sample email:
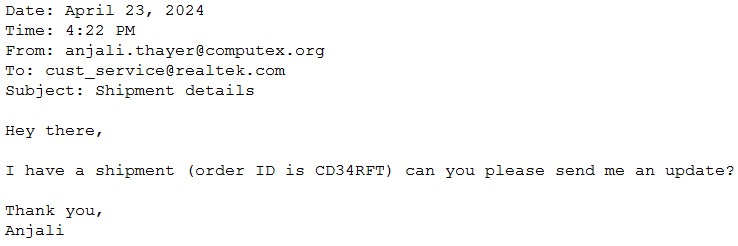
They will need to write a prompt that will extract the relevant information in JSON format with the highest level of output accuracy.
Which prompt will do that?
Problem Context: The goal is to parse emails to extract certain pieces of information and output this in a structured JSON format. Clarity and specificity in the prompt design will ensure higher accuracy in the LLM's responses.
Explanation of Options:
Option A: Provides a general guideline but lacks an example, which helps an LLM understand the exact format expected.
Option B: Includes a clear instruction and a specific example of the output format. Providing an example is crucial as it helps set the pattern and format in which the information should be structured, leading to more accurate results.
Option C: Does not specify that the output should be in JSON format, thus not meeting the requirement.
Option D: While it correctly asks for JSON format, it lacks an example that would guide the LLM on how to structure the JSON correctly.
Therefore, Option B is optimal as it not only specifies the required format but also illustrates it with an example, enhancing the likelihood of accurate extraction and formatting by the LLM.
A Generative AI Engineer is designing an LLM-powered live sports commentary platform. The platform provides real-time updates and LLM-generated analyses for any users who would like to have live summaries, rather than reading a series of potentially outdated news articles.
Which tool below will give the platform access to real-time data for generating game analyses based on the latest game scores?
Problem Context: The engineer is developing an LLM-powered live sports commentary platform that needs to provide real-time updates and analyses based on the latest game scores. The critical requirement here is the capability to access and integrate real-time data efficiently with the platform for immediate analysis and reporting.
Explanation of Options:
Option A: DatabricksIQ: While DatabricksIQ offers integration and data processing capabilities, it is more aligned with data analytics rather than real-time feature serving, which is crucial for immediate updates necessary in a live sports commentary context.
Option B: Foundation Model APIs: These APIs facilitate interactions with pre-trained models and could be part of the solution, but on their own, they do not provide mechanisms to access real-time game scores.
Option C: Feature Serving: This is the correct answer as feature serving specifically refers to the real-time provision of data (features) to models for prediction. This would be essential for an LLM that generates analyses based on live game data, ensuring that the commentary is current and based on the latest events in the sport.
Option D: AutoML: This tool automates the process of applying machine learning models to real-world problems, but it does not directly provide real-time data access, which is a critical requirement for the platform.
Thus, Option C (Feature Serving) is the most suitable tool for the platform as it directly supports the real-time data needs of an LLM-powered sports commentary system, ensuring that the analyses and updates are based on the latest available information.
A Generative AI Engineer is developing an agent system using a popular agent-authoring library. The agent comprises multiple parallel and sequential chains. The engineer encounters challenges as the agent fails at one of the steps, making it difficult to debug the root cause. They need to find an appropriate approach to research this issue and discover the cause of failure. Which approach do they choose?
For complex agentic systems (like those built with LangGraph or Autogen), standard logging is often insufficient because the 'state' of the agent changes dynamically. MLflow Tracing is the designated Generative AI engineering standard for debugging these systems. Tracing provides a visual, hierarchical timeline of every call made during an agent's execution---including internal LLM reasoning, tool calls, and data transformations. When a step fails, the trace allows the engineer to click into that specific node to see the exact input sent to the LLM and the raw output received. This is much faster and more comprehensive than manually deconstructing the agent (D) or adding manual logs (C). While mlflow.evaluate (B) is useful for measuring performance across a whole dataset, it is not a tool for real-time debugging of a single execution failure.
- Select Question Types you want
- Set your Desired Pass Percentage
- Allocate Time (Hours : Minutes)
- Create Multiple Practice tests with Limited Questions
- Customer Support
Crystal Wilson
16 days agoBrenda Lopez
24 days agoBetty Edwards
2 months agoPaul Davis
2 months agoWilliam Williams
2 months agoLaura Lee
2 months agoRonald Wilson
2 months agoDonna Baker
2 months agoAshley Murphy
2 months agoJason Anderson
2 months agoFabiola
3 months agoCecily
3 months agoKrystal
3 months agoLynelle
4 months agoMarylou
4 months agoAngella
4 months agoWillard
5 months agoGilberto
5 months agoInes
5 months agoJames
5 months agoGilbert
6 months agoColette
6 months agoTegan
6 months agoSylvia
6 months agoHubert
7 months agoCarlene
7 months agoTayna
7 months agoTitus
7 months agoGwenn
8 months agoKatie
8 months agoDaryl
8 months agoMalcolm
8 months agoMarlon
9 months agoWilbert
9 months agoKattie
9 months agoBritt
9 months agoNaomi
10 months agoLore
10 months agoPaul
12 months agoElinore
1 year agoBobbie
1 year agoShannon
1 year agoAhmad
1 year agoJoni
1 year agoEmogene
1 year agoElke
1 year agoToshia
2 years agoMatthew
2 years agoMari
2 years agoDeangelo
2 years agoVirgilio
2 years agoDewitt
2 years agoDesmond
2 years agoMy
2 years agoSherrell
2 years agoMila
2 years agoCarri
2 years agoAntonette
2 years agoOcie
2 years ago