Deal of The Day! Hurry Up, Grab the Special Discount - Save 25% - Ends In 00:00:00 Coupon code: SAVE25
Free Preparation Discussions
Amazon Exam MLS-C01 Topic 10 Question 16 Discussion
Actual exam question for
Amazon's
MLS-C01 exam
Question #: 16
Topic #: 10
[All MLS-C01 Questions]
Topic #: 10
A company wants to classify user behavior as either fraudulent or normal. Based on internal research, a Machine Learning Specialist would like to build a binary classifier based on two features: age of account and transaction month. The class distribution for these features is illustrated in the figure provided.
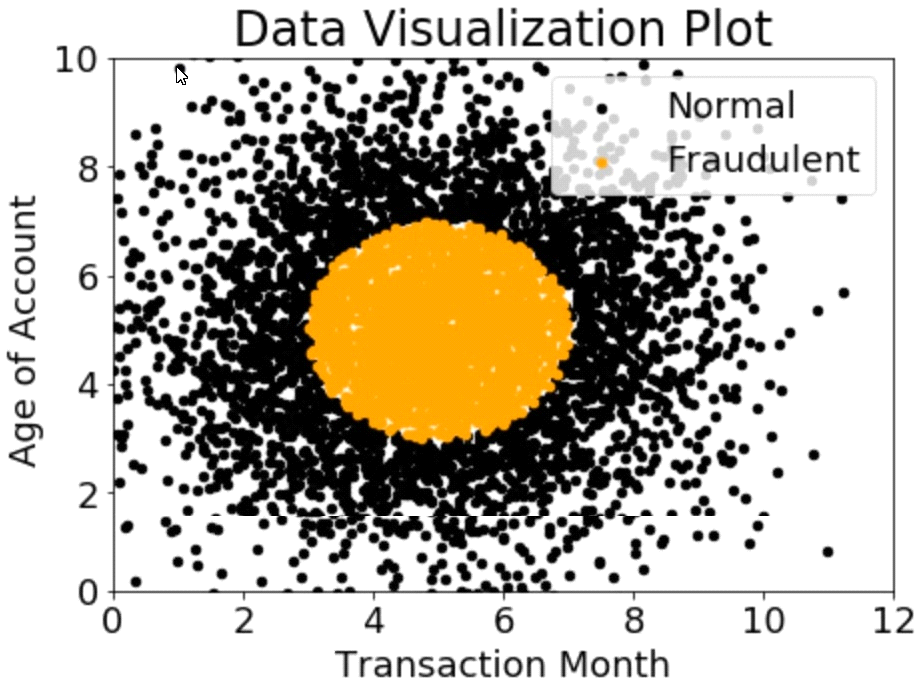
Based on this information, which model would have the HIGHEST recall with respect to the fraudulent class?
Suggested Answer:
C
Currently there are no comments in this discussion, be the first to comment!